Gate #2 of 10 in a series on what it takes to move an AI agent from a convincing demo to something you could put in front of a regulator. This piece expands on a shorter post. It uses an anonymized example from a personal project built on public data. It is not a product, and nothing here is financial or legal advice.
The report that looked perfect
A while back, one of my AI agents handed me a due-diligence report on a company. It was clean. It was well organized. It had an executive summary, a financial section, a risk section, and a recommendation. It looked like something a careful junior analyst might produce after a solid afternoon of work.
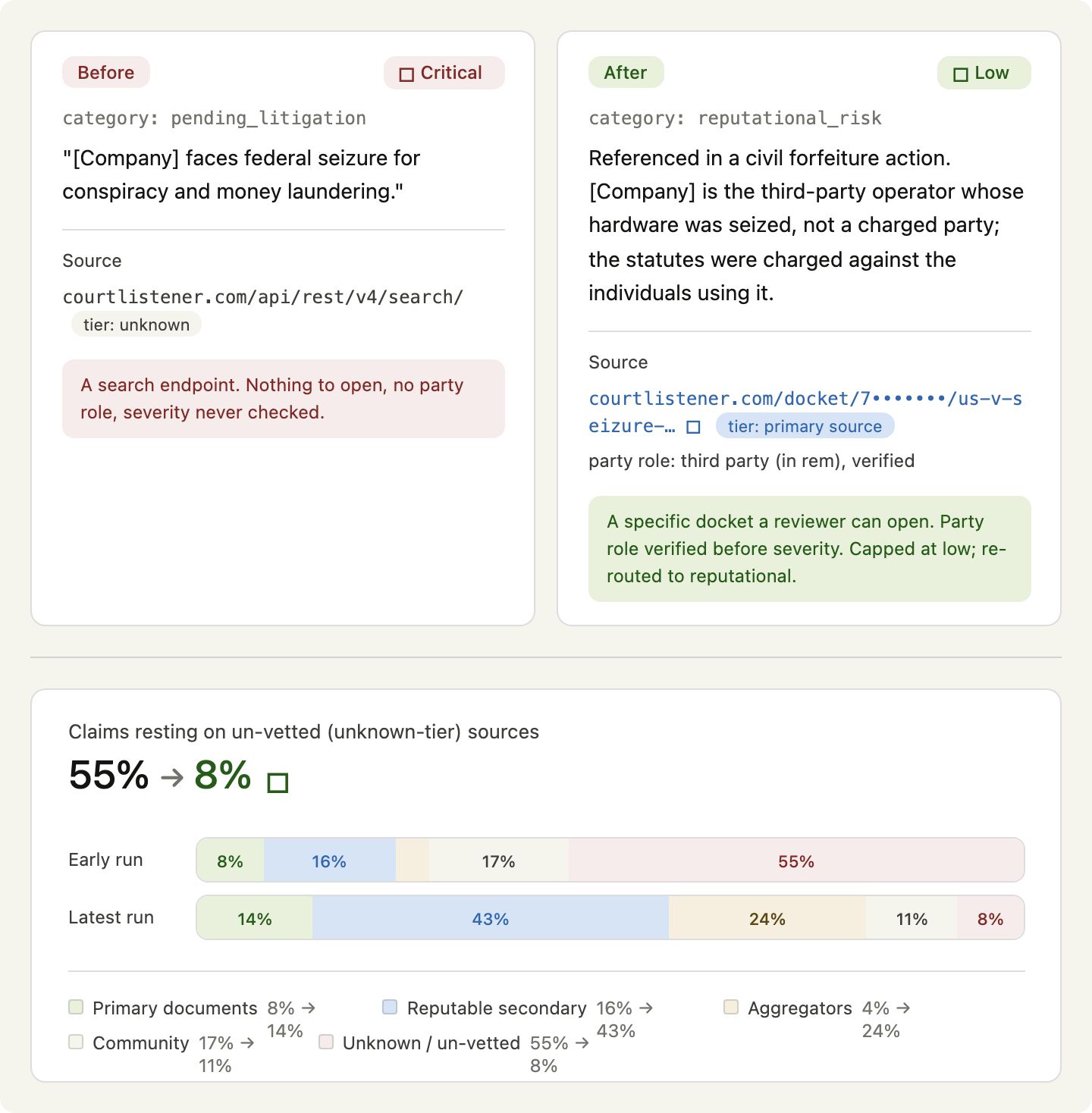
Buried in the risk section was a single line, marked CRITICAL: the company faced federal seizure in a case involving conspiracy and money laundering.
If that were true, it would be the most important sentence in the entire report. It would change the recommendation. It would change whether anyone should do business with this company at all. And it was stated with exactly the same calm confidence as every other line in the document.
It was also completely wrong.
Why this is the failure that should scare you
When people worry about AI agents, they usually picture the dramatic failures. The model crashes. It returns gibberish. It says something so absurd that any reader catches it in a second.
Those are not the failures that keep me up at night. Those get caught.
The failure that should worry anyone deploying an agent into a high-stakes setting is the one I just described: a confident, plausible, well-formatted wrong answer. It does not look like a bug. It looks like a finding. It wears the same costume as every correct line around it, and there is nothing on the surface that tells a reader which is which.
In a demo, this failure is invisible. You ask the agent about three companies you already know, the output looks great, everyone nods, and the meeting moves on. The first time it matters is the first time someone acts on a sentence that happens to be wrong, and by then the cost is real and it belongs to a person, not to a slide.
What actually went wrong
Here is what the agent did, and it is worth understanding because the mistake is so reasonable.
It found a real federal court record. The record was genuine. The company’s name really did appear in it. But the case was an asset forfeiture. The government was seizing specific equipment that a criminal operation had been using. The company was a cooperating third party whose product had been misused by other people. It was not a defendant. The serious charges — the conspiracy and the money laundering — were aimed at the actual operators of the scheme, not at the company.
The agent collapsed all of that into one sentence. “This company’s name appears in a criminal court record” became “this company faces criminal charges.” It is a subtle move and a total error. The difference between being named in a docket and being the defendant in it is the entire difference between a cooperating business and a criminal one.
A human analyst who read the underlying filing would never make this mistake, because a human reads the case and understands the roles in it. The agent did not understand roles. It matched a company name against frightening words in a legal document and reported the match as a fact.
The tempting fix, and the real one
The tempting fix took about five minutes to think of. Add a rule: when the agent sees this kind of case, or these particular words, downgrade the severity. Patch the specific failure and move on.
That temptation is the strongest pull I have found between building a demo and building something real. The patch works. It makes this exact report correct. It would pass any test written around this exact case. And it fixes nothing, because the next company will turn up in a different document with a different shape, and the agent will misread that one too.
The real problem was never the words in this case. The problem was that the agent had no idea where any of its claims came from, or what role the company played in the source behind them. It treated “I found this” and “this is true about the company” as the same thing. There was no layer in the system whose job was to ask: what is the source, how much should we trust it, and what does it say about this specific entity?
So the real fix was structural, and it had a name. Provenance.
What provenance actually means
Provenance is an old idea from the art world. It is the documented chain of custody that tells you where a painting came from and why you should believe it is real. For an AI agent, provenance means something close to that. Every claim the system makes should carry its origin with it, and the system should reason about that origin before it asserts anything.
In practice that breaks into two questions the old version of my agent never asked.
The first is about trust. Where did this come from, and how much weight does that source deserve? A filing from a government regulator is not the same kind of evidence as a sentence on an anonymous blog, and a system that treats them as equal is going to be confidently wrong on a regular schedule.
The second is about meaning. What does the source say about this company? Being named in a document is not the same as being the subject of it. That is the exact distinction the agent missed, and no amount of trusting the source would have saved it, because the source was real. The agent trusted a genuine document and still drew a false conclusion from it.
A provenance-first system has to answer both questions for every claim, before that claim is allowed into the report.
Turning trust into a number
The trust question is the one I could make concrete, so I started there. I built a tiered model of source quality. At the top are primary documents: government filings, court records, regulatory databases, the original artifacts themselves. Below that are reputable secondary sources, the established news organizations that do real reporting. Below that are aggregators, the sites that repackage other people’s data. Below that is community content, the forums and social posts and review sites. And at the bottom is everything unknown — the sources that could not be placed at all.
Every claim in a report now carries the tier of the source behind it. That sounds like a small bookkeeping change. It is not. It turns the trustworthiness of a report from a feeling into a measurement.
Once you can measure something, you can watch it improve. Across successive versions of the system, I tracked the share of claims resting on each tier. In the early versions, more than half of all claims sat on unknown sources. That is a frightening number once you can see it, because it means most of what the report asserted could not be traced to anything you would trust. Over later iterations, that unknown share fell to under ten percent, while the share backed by primary and reputable sources climbed. The reports did not always look very different on the surface. Underneath, they had moved from mostly unsupported to mostly traceable.
One caveat that matters, because this whole series is about not overclaiming. That trajectory is measured across different versions of the system over time, not a single clean comparison on one report. It is a direction of travel, not a finished result. But the direction is the point. Provenance gave me a dial I could read, where before there was only a vibe.
The gap is the feature
Here is the part that took me longest to accept, and it sits at the center of all of this.
When the system cannot find a trustworthy source for something, the right behavior is not to reach down to a weak source and fill the gap with a plausible-sounding guess. The right behavior is to leave the gap, and to say so plainly. To record, in the report itself, that this particular thing could not be verified.
In a demo, a gap looks like a weakness. The report has a hole in it. A competing demo with no holes looks more impressive, more complete, more finished. If you are optimizing for the five-minute pitch, you fill every gap, because gaps look like the system failing to do its job.
In production, the gap is the feature. A known unknown is safe. You can see it, you can decide whether to go find the answer yourself, you can choose not to lean on that part of the report. A confident unknown is the dangerous thing. The money-laundering flag was a confident unknown wearing the costume of a finding. The most valuable thing a system in a regulated setting can do is to be honest about the edges of what it knows, because the alternative is not a more complete report. The alternative is a report that misleads you most smoothly in exactly the places it is weakest.
I would now rather ship a system that tells me “I could not verify this” than one that always has an answer. The one that always has an answer is the one that produced the money-laundering flag.
What it costs
None of this is free, and the price is worth naming, because the price is the reason most demos skip it.
A provenance-first system is slower to build. The reports are sometimes less polished and less complete-looking, because they refuse to assert things they cannot support. In a head-to-head demo against a flashier agent that fills every field with a confident sentence, mine can look like the more cautious, less capable one.
That comparison flips completely the moment the output touches a real decision. The flashy version becomes a liability the first time someone acts on one of its unsupported sentences. The cautious version becomes an asset, because everything it tells you can be checked, and everything it cannot tell you, it admits. The value was never in how finished the report looked. The value is in whether you can trust it when it matters, and trust you cannot trace is not trust. It is hope.
This is the same idea that runs through the whole series. A demo optimizes for looking right. A production system optimizes for being checkable. Those are not the same goal, and most of the work of moving from one to the other lives in places a demo will never show you.
What I am still working on
I will not pretend this is solved, because it is not, and a piece about provenance that overclaimed its own provenance would be a strange thing to publish.
A few things are still ahead of me. The system bounds its confidence by the tier of the source, but it does not yet calibrate that confidence against real outcomes, which would take a body of verified results to learn from. It tracks the source of each claim, but not yet the exact passage inside that source that supports it, so the provenance is at the level of “this document” rather than “this sentence.” And when two sources disagree, the system flags the conflict but does not resolve it. Those are later gates, and I will write about them as I build them.
Where this fits
Provenance is the second of ten gates I think an AI agent has to pass before it belongs anywhere near a regulated decision. The first was the audit trail — the ability to reconstruct what the system did and why. Provenance is the one that turns a confident wrong answer into a traceable one, which is the difference between a mistake you can catch and a mistake that ships.
The gap between an agent that scores two out of ten on these gates and one that scores ten out of ten is almost entirely invisible in a demo. It becomes visible the first time someone asks the only question that matters in a high-stakes setting: where did this come from?
Next in the series is Gate #3, per-claim confidence, which is what you build once you can trace where everything came from and you start asking how sure you really are.
The project is a personal one, built in the open on public data. The code is linked from the repository if you want to see the machinery behind any of this. And if you are building agents that have to survive contact with a real decision, I would be glad to compare notes.